
REGEX.EXTRACT
Fungsi REGEX.EXTRACT menghasilkan kecocokan atau grup pengambilan di kecocokan ekspresi reguler yang ditentukan di string sumber.
REGEX.EXTRACT(source-string, regular-expression-string, match-occurrence, capture-group-occurrence)
source-string: Nilai string untuk dicocokkan.
regular-expression-string: Nilai string yang mewakili ekspresi reguler, yang digunakan untuk dicocokkan dengan source-string.
match-occurrence: Integer opsional yang menandakan kecocokan mana yang harus dihasilkan, jika terdapat beberapa kecocokan. Integer negatif diterima dan memungkinkan akses kecocokan ke belakang, sehingga -1 adalah kecocokan terakhir, dan seterusnya. Jika 0 ditentukan, larik semua kecocokan akan dihasilkan. Jika dihilangkan, kecocokan pertama dihasilkan.
capture-group-occurrence: Integer opsional yang menandakan grup pengambilan mana dalam kecocokan yang harus dihasilkan, jika terdapat grup pengambilan di ekspresi reguler. Nilai negatif tidak diterima. Jika 0 dihasilkan, larik semua grup pengambilan akan dihasilkan. Jika dihilangkan, seluruh kecocokan dihasilkan.
Catatan
regular-expression-string harus sesuai dengan standar ICU.
Contoh |
|---|
Jika Anda memiliki data yang tidak cocok ke baris dan kolom spreadsheet, Anda dapat menggunakan REGEX.EXTRACT untuk menyederhanakannya. Misalnya, di tabel di bawah, data memiliki beberapa struktur, tapi data sulit dipisahkan secara manual ke beberapa sel per ulasan. |
A | |
|---|---|
1 | Ulasan Pengguna |
2 | Email: jtalma@icloud.com Nama: Julie Talma Tanggal: 17/05/2021 |
3 | Email: danny_rico@icloud.com Nama: Danny Rico Tanggal: 02/06/2021 |
Untuk memperbaiki ini, Anda dapat menambahkan kolom lainnya ke tabel untuk Nama, Email, Nilai, dan Tanggal, lalu menggunakan REGEX.EXTRACT untuk menemukan data yang Anda inginkan dan menghasilkannya di sel. Misalnya, Anda dapat memasukkan formula berikut untuk menghasilkan nama: 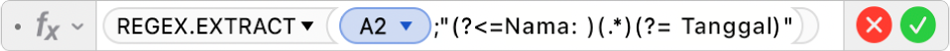 Di formula ini, argumen berikut digunakan:
Formula dapat diulang untuk setiap baris data untuk menghasilkan nama setiap orang yang merespons survei dengan mengubah source-string agar sesuai dengan sel lainnya yang berisi informasi ulasan pengguna. |
Untuk memperbaiki ini, Anda dapat menambahkan kolom lainnya ke tabel untuk Nama, Email, Nilai, dan Tanggal, lalu menggunakan REGEX.EXTRACT untuk menemukan data yang Anda inginkan dan menghasilkannya di sel. Misalnya, Anda dapat memasukkan formula berikut: ![Editor Formula menampilkan formula =REGEX.EXTRACT(A2;"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2;4}")](https://help.apple.com/assets/6467B9B3CF36103D3A318861/6467B9B8CF36103D3A318879/id_ID/4cf045d1cf5172593f426f07e1f58801.png) Di formula ini, argumen berikut digunakan:
|
Menyusun ulang data dari daftar dengan match-occurrence |
|---|
Terkadang, Anda mungkin memiliki data seperti tabel (berjudul Pemasok) di bawah, yang mengelompokkan nilai bersama di sel: |
Pemasok | Item |
|---|---|
A | Lentil, Garbanzo, Kratok |
B | Apel, Jeruk, Lemon |
C | Quinoa, Beras, Chia |
Untuk memisahkan nilai berdasarkan toko dan peringkat, Anda dapat membuat tabel baru terlebih dahulu, seperti tabel di bawah: |
A | B | C | D | |
|---|---|---|---|---|
1 | Peringkat | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
Untuk menghasilkan Lentil, item peringkat teratas untuk Pemasok A, Anda dapat menggunakan formula seperti ini di sel B2 pada tabel baru untuk menghasilkan Lentil, item peringkat teratas untuk Pemasok A:  Di formula ini, argumen berikut digunakan:
|
Formula di atas dapat dimodifikasi dengan mudah untuk melengkapi tabel untuk pemasok dan item lainnya.
|
Contoh tambahan |
|---|
Biarkan A1 berisi "marina@example.com john@example.ca mike@example.de". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") menghasilkan "marina@example.com". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2) menghasilkan "john@example.ca". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; -1) menghasilkan "mikeexample.de". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 1; 1) menghasilkan "marina". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2; 2) menghasilkan "example.ca". |