REGEX.EXTRACT
Funkcija REGEX.EXTRACT vraća podudaranja ili grupe snimanja u podudaranju zadanog regularnog izraza u ishodišnom nizu.
REGEX.EXTRACT(izvor-niz; niz-regularnog-izraza; pojava-podudaranje; snimanje-grupa-pojava)
izvor-niz: Vrijednost niza koja se treba podudarati.
niz-regularnog-izraza: Vrijednost niza koja predstavlja regularni izraz, upotrebljava se za podudaranje s vrijednosti izvor-niz.
podudaranje-pojava: Opcionalni cijeli broj koji označava koje se podudaranje treba vratiti, u slučaju ako postoji više podudaranja. Prihvaćaju se negativni cijeli brojevi i omogućavaju pristup podudaranjima unatrag, tako da je -1 najmanje podudaranje, i tako dalje. Ako je dana 0, vraća se niz svih podudaranja. Ako se izostavi, vraća se prvo podudaranje.
snimanje-grupa-pojava: Opcionalni cijeli broj koji označava koja se grupa snimanja u okviru podudaranja treba vratiti, u slučaju da postoje grupe podudaranja u regularnom izrazu. Ne prihvaćaju se negativne vrijednosti. Ako se 0 vrati, vraća se niz svih grupa snimanja. Ako se izostavi, vraća se cijelo podudaranje.
Napomene
niz-regularnog-izraza mora biti u skladu sa standardom ICU.
Primjeri |
|---|
Ako imate podatke koji ne mogu jednostavno stati u retke i stupce tabličnog dokumenta, za pojednostavnjenje možete koristiti funkciju REGEX.EXTRACT. Primjerice, u donjoj tablici podaci imaju neku strukturu, ali može biti teško ručno razdvojiti podatke u više ćelija po ocjeni. |
A | |
|---|---|
1 | Ocjene korisnika |
2 | E-mail: jtalma@icloud.com Ime: Julija Talmar Datum: 17/05/2021 |
3 | E-mail: danny_rico@icloud.com Ime: Danijel Rebar Datum: 02/06/2021 |
Kako biste ovo popravili, možete dodati više stupaca u tablicu za Ime, E-mail, Ocjenu i Datum, a zatim koristiti REGEX.EXTRACT za pronalaženje podataka koje želite i njihovo vraćanje u ćeliju. Primjerice, mogli biste unijeti sljedeću formulu za vraćanje imena: 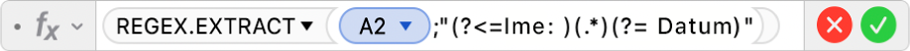 U ovoj formuli koriste se sljedeći argumenti:
Ova se formula može ponoviti za svaki redak podataka kako bi se vratilo ime svake osobe koja je odgovorila na upitnik promjenom izvor-niz kako bi se podudarao s drugim ćelijama koje sadrže informacije o ocjenama korisnika. |
Kako biste ovo popravili, možete dodati više stupaca u tablicu za Ime, E-mail, Ocjenu i Datum, a zatim koristiti REGEX.EXTRACT za pronalaženje podataka koje želite i njihovo vraćanje u ćeliju. Primjerice, mogli biste unijeti sljedeću formulu: ![Uređivač formula prikazuje formulu =REGEX.EXTRACT(A2;"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}")](https://help.apple.com/assets/6467B9B3CF36103D3A318861/6467B9B8CF36103D3A318879/hr_HR/4cf045d1cf5172593f426f07e1f58801.png) U ovoj formuli koriste se sljedeći argumenti:
|
Reorganizacija podataka s popisa pomoću podudaranje-pojava |
|---|
Ponekad možete imati podatke poput donje tablice (pod nazivom Dobavljači) koja zajedno grupira vrijednosti u ćeliji: |
Dobavljač | Proizvod |
|---|---|
A | Leća, Slanutak, Lima grah |
B | Jabuke, Naranče, Limunovi |
C | Kvinoja, Riža, Chia |
Kako biste razdvojili vrijednosti na temelju trgovine i ranga, možete prvo izraditi novu tablicu, kao što je donja tablica: |
A | B | C | D | |
|---|---|---|---|---|
1 | Rang | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
Kako bi se vratila Leća, najbolje rangirani proizvod za Dobavljača A, možete koristiti formulu kao što je ova u ćeliji B2 nove tablice kako bi se vratila Leća, najbolje rangirani proizvod Dobavljača A:  U ovoj formuli koriste se sljedeći argumenti:
|
Gornja formula može se jednostavno modificirati kako bi se dovršila tablica za druge dobavljače i proizvode.
|
Dodatni primjeri |
|---|
Neka A1 bude "marina@primjer.com ivan@primjer.ca milan@primjer.de". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") vraća "marina@primjer.com". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2) vraća "john@primjer.ca". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; -1) vraća "milanprimjer.de". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 1; 1) vraća "marina". =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2; 2) vraća "primjer.ca". |