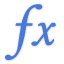
COUNTIF
COUNTIF 函數會傳回某一集合內滿足指定條件之輸入格的數目。
COUNTIF(測試陣列, 條件)
附註
每個測試陣列值都會與條件進行比較。如果值滿足條件測試,則函數會將其包含在計數中。
範例 |
|---|
下表中的資訊沒有實際意義,但可用來說明函數結果中每個 COUNTIF 變數所包含的引數類型。 提供下列表格: |
A | B | C | D | |
|---|---|---|---|---|
1 | 100 | 200 | 300 | 400 |
2 | lorem | ipsum | dolor | sit |
3 | 100 | 200 | 300 | sit |
4 | TRUE | TRUE | FALSE | FALSE |
5 | 200 | 400 |
=COUNTIF(A1:D1, “>0”) 會傳回 4,因為該集合內所有輸入格的值都大於零。 =COUNTIF(A3:D3, “>=100”) 會傳回 3,因為有三個大於或等於 100 的數值,而文字值會在比較時被忽略。 =COUNTIF(A1:D5, “=ipsum”) 會傳回 1,因為文字字串「ipsum」在該範圍所參照的集合內出現一次。 =COUNTIF(A1:D5, “=*t”) 會傳回 2,因為以字母「t」結尾的字串在該範圍所參照的集合內出現兩次。 |
範例:調查結果 |
|---|
此範例一併呈現在整個統計函數中所使用的圖解。它是以假設性的調查為基礎。調查的長度簡短(僅有五個問題),且已有限制數目的應答者(10)。每個問題可以依據 1 到 5 的程度來回答(可能範圍是從「從不」到「總是」)或不予以回答。每個調查在郵寄前會被指定一個編號 (ID#)。下表即顯示結果。回答超出範圍(不正確)或未回答的問題,在表格中會以空白輸入格表示。 |
A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
1 | ID# | Q1 | Q2 | Q3 | Q4 | Q5 |
2 | 101 | 5 | 4 | 4 | 3 | 4 |
3 | 105 | 3 | 2 | 2 | 3 | 3 |
4 | 102 | 4 | 4 | 4 | 4 | |
5 | 104 | 3 | 4 | 2 | 4 | 3 |
6 | 107 | 4 | 3 | 3 | ||
7 | 106 | 4 | 3 | 3 | 4 | |
8 | 109 | 3 | 4 | 1 | 3 | 4 |
9 | 111 | 5 | 2 | 2 | 5 | 3 |
10 | 121 | 4 | 2 | 3 | 3 | 4 |
11 | 115 | 3 | 3 | 3 | 3 |
為了以圖解說明部分函數,假定調查編號已包含字母字首,且程度是 A–E,而非 1–5。此表看起來會像這樣: |
A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
1 | ID# | Q1 | Q2 | Q3 | Q4 | Q5 |
2 | 101 | E | D | D | C | D |
3 | 105 | C | B | B | C | C |
4 | 102 | D | D | D | D | |
5 | 104 | C | D | B | D | C |
6 | 107 | D | C | C | ||
7 | 106 | D | C | C | D | |
8 | 109 | C | D | A | C | D |
9 | 111 | E | B | B | E | C |
10 | 121 | D | B | C | D | |
11 | 115 | C | C | C | C | C |
使用此資料表和部分可用統計函數,您可以收集有關調查結果的資訊。請牢記,此範例是刻意縮小規模,因此結果可能會頗為明顯。不過,如果您有 50 位、100 位或更多的應答者,且或許有更多的問題,結果可能不會這麼明顯。 |
函數和引數 | 結果描述 |
|---|---|
=CORREL(B2:B11, C2:C11) | 使用線性迴歸分析來決定問題 1 和問題 2 的相互關係。相互關係是兩個變數彼此連動的程度測量值(在此情況下,為答案與調查的問題)。明確地說,這會視問題而定:如果應答者使用較高(或較低)的值來回答問題 1,而非問題 1 的平均值,應答者是否也會以較高(或較低)的值來回答問題 2,而非問題 2 的平均值?在此情況下,回應並沒有特別相關聯(-0.1732) |
=COUNT(A2:A11) 或 =COUNTA(A2:A11) | 決定所傳回的調查總數(10)。請注意,如果調查編號不是數值,您需要使用 COUNTA,而非 COUNT。 |
=COUNT(B2:B11) 或 =COUNTA(B2:B11) | 決定第一個問題的回答總數(9)。透過將此公式延伸過橫列,您可以決定每個問題的回答總數。因為所有資料皆為數值,COUNTA 會傳回相同的結果。不過,如果調查已使用 A 到 E,而非 1 到 5,您需要使用 COUNTA 來計算結果。 |
=COUNTBLANK(B2:B11) | 決定空輸入格的數目,其表示無效或沒有答案。如果您將此公式延伸過橫列,會發現問題 3(直欄 D)有 3 個無效或未回答的回應。這可能會讓您複查此調查上的問題,以查看其是否有爭議或用詞不佳,因為沒有其他問題有超過 1 個不正確或未回答的回應。 |
=COUNTIF(B2:B11, “=5”) | 決定對特定問題回答 5 的回應者數(在此情況下為問題 1)。如果您將此公式延伸過橫列,會得知僅問題 1 和 4 有任一回應者對問題回答 5。如果調查使用 A 到 E 作為範圍,您便會使用 =COUNTIF(B2:B11, “=E”)。 |
=COVAR(B2:B11, C2:C11) | 決定問題 1 和問題 2 的共變異數。共變異數是兩個變數彼此連動的程度測量值(在此情況下,為答案與調查的問題)。明確地說,這會視問題而定:如果應答者使用較高(或較低)的值來回答問題 1,而非問題 1 的平均值,應答者是否也會以較高(或較低)的值來回答問題 2,而非問題 2 的平均值? 附註:COVAR 無法用於使用 A–E 作為範圍的表格,因為其需有數值引數。 |
=STDEV(B2:B11) 或 =STDEVP(B2:B11) | 決定對問題 1 之回答的標準差(一種離散量數)。如果您將此公式延伸過橫列,會看到對問題 3 的回答具有最高的標準差。如果結果代表來自所研究之整個母群體的回應,而非樣本,便會使用 STDEVP,而非 STDEV。請注意,STDEV 是 VAR 的平方根。 |
=VAR(B2:B11) 或 =VARP(B2:B11) | 決定對問題 1 之回答的變異數(一種離散量數)。如果您將此公式延伸過橫列,會看到對問題 5 的回答具有最低的變異數。如果結果代表來自所研究之整個母群體的回應,而非樣本,便會使用 VARP,而非 VAR。請注意,VAR 是 STDEV 的平方。 |
使用 REGEX 的範例 |
|---|
提供下列表格: |
A | B | |
|---|---|---|
1 | 45 | john@appleseed.com |
2 | 41 | Aaron |
3 | 29 | janedoe@appleseed.com |
4 | 64 | jake@appleseed.com |
5 | 12 | Sarah |
=COUNTIF(B1:B5, REGEX(“([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})”)) 會傳回 B1:B5 中包含電子郵件地址的輸入格數。 |