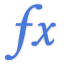
LINEST
LINEST 함수는 최소 자승 방법을 사용하여 주어진 데이터에 가장 적합한 직선에 대한 통계 배열을 반환합니다.
LINEST(알려진 y값, 알려진 x값, 0이 아닌 y절편, 통계)
알려진 y값: 알려진 y값을 포함한 모음입니다. 알려진 y값은 숫자값 또는 날짜/시간값을 포함해야 합니다. 하나의 알려진 x값 모음만 있다면, 알려진 y값은 어떠한 크기도 될 수 있습니다. 하나 이상의 알려진 x값 모음이 있다면, 알려진 y값은 값을 포함하는 하나의 열이나 값을 포함하는 하나의 행이 될 수 있지만, 열과 행 모두 될 수는 없습니다.
알려진 x값: 알려진 x값을 포함한 선택적 모음입니다. 알려진 x값은 숫자값 또는 날짜/시간값을 포함해야 합니다. 생략되어 있을 때 예를 들어 1, 2, 3 세 개의 알려진 y값이 있는 경우, 1로 시작하는 알려진 y값과 동일한 크기의 세트로 간주됩니다. 하나의 알려진 x값 세트만 있다면, 알려진 x값은 알려진 y값과 같은 크기여야 합니다. 하나 이상의 x값 세트가 있다면, 알려진 x값의 각 행/열은 한 세트로 간주되며 각 행/열의 크기는 알려진 y값의 행/열의 크기와 같아야 합니다.
0이 아닌 y절편: y절편(상수 b)을 계산하는 방법을 지정하는 선택적 모달값입니다.
일반(1, TRUE 또는 생략됨): y절편 값(상수 b)이 일반적으로 계산되어야 합니다.
0값 강제(0, FALSE): y절편 값(상수 b)이 0이 되도록 강제합니다.
통계: 추가 통계 정보를 반환해야 하는지 여부를 지정하는 선택적 모달값입니다.
추가 통계 없음(0, FALSE 또는 생략됨): 반환된 배열에 추가 회귀 통계를 반환하지 않습니다.
추가 통계(1, TRUE): 반환된 배열에 추가 회귀 통계를 반환합니다
참고
함수에 의해 반환된 값은 배열에 포함됩니다. 배열이 있는 값들을 읽는 한가지 방법은 INDEX 함수를 사용하는 것입니다. INDEX 함수 안에 LINEST 함수를 포함할 수 있습니다. =INDEX(LINEST(알려진 y값, 알려진 x값, y절편, 추가 통계), y, x) 수식에서 y와 x는 희망 값의 열과 행 인덱스입니다.
추가 통계가 반환되지 않으면(추가 통계가 FALSE이면) 반환된 배열은 1행입니다. 열의 수는 알려진 x값의 세트 수 더하기 1과 같습니다. 역순(x값의 마지막 행/열에 관한 첫 번째 값)으로 선 기울기(x값의 각 행/열에 대한 하나의 값)와 b에 대한 값, 절편을 포함합니다.
추가 통계가 반환되면(추가 통계가 TRUE이면) 배열은 다섯 개의 행을 포함합니다. 예제 바로 다음에 나오는 이 배열에 관한 추가 정보를 참조하십시오.
예제 |
|---|
다음은 알려진 x값(셀 A2:A6) 및 알려진 y값(셀 B2:B6)의 표입니다. |
A | B | |
|---|---|---|
1 | X | Y |
2 | 0 | -1 |
3 | 8 | 10 |
4 | 9 | 12 |
5 | 4 | 5 |
6 | 1 | 3 |
=INDEX(LINEST(A2:A6, B2:B6, 1, 0), 1) 함수는 0이 아닌 y절편에 대한 정규(1) 값인 약 0.752707581227437을 반환합니다. 이것은 INDEX에서 반환된 배열의 첫 번째 값을 얻도록 지정했으며 알려진 x값의 한 세트만 지정했기 때문에 선의 기울기입니다. =INDEX(LINEST(A2:A6, B2:B6, 1, 0), 2) 함수는 b, 선 절편인 약 0.0342960288808646을 반환합니다. INDEX에서 반환된 배열의 두 번째 값을 얻도록 지정했기 때문에(알려진 x값의 한 세트만 지정했기 때문에 두 번째 값) 절편이 반환됩니다. |
추가 통계 배열의 내용
LINEST는 함수에 의해 반환된 배열에 추가 통계 정보를 포함할 수 있습니다. 다음의 설명을 위해, 알려진 x값 5세트와 알려진 y값이 있다고 가정해 봅시다. 알려진 x값은 5개의 표 행이나 5개의 표 열에 있다고 가정합니다. 이것을 기반으로 LINEST에서 반환된 배열에는 다음 값이 포함됩니다.
1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
1 | S5 | S4 | S3 | S2 | S1 | b |
2 | SE5 | SE4 | SE3 | SE2 | SE1 | SEb |
3 | C | SEy | ||||
4 | F | DF | ||||
5 | R1 | R2 |
1행, 1열은 S5(알려진 x값의 다섯 번째 세트 기울기)를 포함하며 S1(알려진 x값의 첫 번째 세트 기울기)을 포함하는 5행까지 이어집니다. 각 알려진 x값 세트와 관련된 기울기가 역순으로 반환됩니다.
1행의 마지막 셀에 알려진 x값에 대한 y절편인 b가 포함됩니다. 이 예제에서는 1행 6열이 됩니다.
2행, 1열은 SE5(알려진 x값의 다섯 번째 세트와 연관된 계수에 대한 표준 오류)를 포함하며 SE1(알려진 x값의 첫 번째 세트와 관련된 계수에 대한 표준 오류)을 포함하는 5행까지 이어집니다. 이 값은 역순으로 반환됩니다. 즉, 5개의 알려진 x값 세트가 있다면, 다섯 번째 세트에 대한 값이 배열에서 첫 번째로 반환됩니다. 이것은 기울기 값이 반환되는 방법과 같습니다.
2행의 마지막 셀은 y절편값(b)과 연관된 표준 오류인 SEb를 포함합니다. 이 예제에서는 2행 6열이 됩니다.
3행, 1열에는 결정 계수인 C가 포함됩니다. 이 통계치는 예상 y값과 실제 y값을 비교합니다. 1이면, 예상 y값과 실제 y값 사이에 차이가 없습니다. 이것은 완전 상관 관계라고 합니다. 결정 계수가 0이면, 상관 관계가 없고 주어진 회귀 방정식은 y값을 예상하는데 도움이 되지 않습니다.
3행, 2열은 y값 추정과 연관된 표준 오류인 SEy를 포함합니다.
4행, 1열에는 F 관측값인 F가 포함됩니다. F 관측값은 독립과 종속 변수 간의 관측 관계가 우연히 발생하는지를 결정하는 데 사용될 수 있습니다.
4행, 2열에는 자유도인 DF가 포함됩니다. 자유 통계의 정도를 사용하여 신뢰 단계를 결정하는 데 도움을 받을 수 있습니다.
5행, 1열은 회귀 제곱합인 R1을 포함합니다.
5행, 2열은 잔여 제곱합인 R2를 포함합니다.
추가 통계 배열에 대해 유의해야 할 몇 가지 사항이 있습니다.
알려진 x값과 알려진 y값이 행이나 열에 있는지는 상관이 없습니다. 두 경우 모두 반환된 배열은 표에 나타난 대로 행에 의해 순서가 정해집니다.
예제는 알려진 x값의 다섯 세트를 가정합니다. 약 5개가 있었다면, 반환된 배열에서 열의 수는 그에 따라 변경되지만(항상 알려진 x값의 세트 수 더하기 1과 같음), 행의 수는 그대로 남아 있습니다.
추가 통계가 LINEST의 인수에 지정되지 않으면 반환된 배열은 첫 번째 행만 포함합니다.