公式與函數輔助說明
- 歡迎使用
-
- ACCRINT
- ACCRINTM
- BONDDURATION
- BONDMDURATION
- COUPDAYBS
- COUPDAYS
- COUPDAYSNC
- COUPNUM
- CUMIPMT
- CUMPRINC
- CURRENCY
- CURRENCYCODE
- CURRENCYCONVERT
- CURRENCYH
- DB
- DDB
- DISC
- EFFECT
- FV
- INTRATE
- IPMT
- IRR
- ISPMT
- MIRR
- NOMINAL
- NPER
- NPV
- PMT
- PPMT
- PRICE
- PRICEDISC
- PRICEMAT
- PV
- RATE
- RECEIVED
- SLN
- STOCK
- STOCKH
- SYD
- VDB
- XIRR
- XNPV
- YIELD
- YIELDDISC
- YIELDMAT
-
- AVEDEV
- AVERAGE
- AVERAGEA
- AVERAGEIF
- AVERAGEIFS
- BETADIST
- BETAINV
- BINOMDIST
- CHIDIST
- CHIINV
- CHITEST
- CONFIDENCE
- CORREL
- COUNT
- COUNTA
- COUNTBLANK
- COUNTIF
- COUNTIFS
- COVAR
- CRITBINOM
- DEVSQ
- EXPONDIST
- FDIST
- FINV
- FORECAST
- FREQUENCY
- GAMMADIST
- GAMMAINV
- GAMMALN
- GEOMEAN
- HARMEAN
- INTERCEPT
- LARGE
- LINEST
- LOGINV
- LOGNORMDIST
- MAX
- MAXA
- MAXIFS
- MEDIAN
- MIN
- MINA
- MINIFS
- MODE
- NEGBINOMDIST
- NORMDIST
- NORMINV
- NORMSDIST
- NORMSINV
- PERCENTILE
- PERCENTRANK
- PERMUT
- POISSON
- PROB
- QUARTILE
- RANK
- SLOPE
- SMALL
- STANDARDIZE
- STDEV
- STDEVA
- STDEVP
- STDEVPA
- TDIST
- TINV
- TTEST
- VAR
- VARA
- VARP
- VARPA
- WEIBULL
- ZTEST
- 版權聲明
REGEX.EXTRACT
REGEX.EXTRACT 函數會傳回來源字串中指定的比對常規表示式中的相符項目或擷取群組。
REGEX.EXTRACT(來源字串, 規則表示式字串, 符合次數, 擷取群組次數)
來源字串: 用來比對的字串值。
規則表示式字串: 表示規則表示式的字串值,用來比對來源字串。
符合次數: 如果有多個符合項目,可選填一個整數,表示應傳回哪一個符合項目。 可接受負值整數並允許向後取用符合項目,因此 -1 是最後的符合項目,以此類推。若指定為 0,將會傳回所有符合項目的陣列。若省略,則會傳回第一個符合項目。
擷取群組次數: 如果常規表示式中有擷取群組,可選填一個整數,表示符合項目中應傳回哪一個擷取群組。 不接受負數值。若指定為 0,將會傳回所有擷取群組的陣列。若省略,則會傳回整個符合項目。
附註
規則表示式字串必須遵守 ICU 標準。
範例 |
|---|
如果你有資料無法輕易符合試算表的橫列和直欄範圍,可使用 REGEX.EXTRACT 加以簡化。例如,下表中的資料結構都相同,但很難手動將資料分隔到每個檢閱畫面的多個輸入格中。 |
A | |
|---|---|
1 | 使用者評論 |
2 | 電子郵件信箱:jtalma@icloud.com 姓名:Julie Talma 日期:2021/5/17 |
3 | 電子郵件信箱:danny_rico@icloud.com 姓名:Danny Rico 日期:2021/6/2 |
為修正此問題,你可以在表格中為「姓名」、「電子郵件」、「評分」和「日期」新增更多直欄,然後使用 REGEX.EXTRACT 尋找需要的資料並傳回輸入格中。 例如,你可以輸入下列公式以傳回姓名: 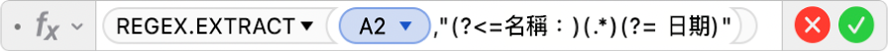 這個公式中使用了以下引數:
你可將來源字串變更為符合包含使用者評論資訊的其他輸入格,為資料的每一列重複執行此公式,藉此傳回有回答問卷的所有人姓名。 |
為修正此問題,你可以在表格中為「姓名」、「電子郵件」、「評分」和「日期」新增更多直欄,然後使用 REGEX.EXTRACT 尋找需要的資料並傳回輸入格中。 例如,你可以輸入下列公式: ![「公式編輯器」顯示公式 =REGEX.EXTRACT(A2,"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}")](https://help.apple.com/assets/626C4EEE69937F618B403B14/626C4EF369937F618B403B34/zh_TW/163c35aaef2fd6a143c84ba471bce0a9.png) 這個公式中使用了以下引數:
|
使用符合次數辨識列表中的資料 |
|---|
有時你的資料可能會像下表(標題為「供應商」)一樣,將值集中在一個輸入格中: |
供應商 | 項目 |
|---|---|
A | 扁豆, 鷹嘴豆, 皇帝豆 |
B | 蘋果, 柳橙, 檸檬 |
C | 藜麥, 米, 奇亞籽 |
若要根據分數和等級將值分隔,你可以先建立一個新表格,例如下表: |
A | B | C | D | |
|---|---|---|---|---|
1 | Rank | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
若要傳回「扁豆」(供應商 A 等級最高的項目),你可以在新表格的輸入格 B2 中使用類似這個公式,以傳回「扁豆」(供應商 A 等級最高的項目):  這個公式中使用了以下引數:
|
你可輕鬆修改上方公式,為其他供應商和其他項目完成表格。
|
其他範例 |
|---|
讓 A1 等於 "marina@example.com john@example.ca mike@example.de"。 =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") 會傳回「marina@example.com」。 =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 2) 會傳回「john@example.ca」。 =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", -1) 會傳回「mikeexample.de」。 =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 1, 1) 會傳回「marina」。 =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 2, 2) 會傳回「example.ca」。 |