REGEX.EXTRACT
Funkcia REGEX.EXTRACT vráti zhody alebo zaznamenané skupiny v zhode daného regulárneho výrazu v zdrojovom reťazci.
REGEX.EXTRACT(zdrojový reťazec; reťazec regulárneho výrazu; výskyt zhody; výskyt zaznamenávaných skupín)
zdrojový reťazec: Hodnota reťazca, ktorá sa má spárovať.
reťazec bežného výrazu: Hodnota reťazca predstavujúceho regulárny výraz použitý na porovnanie so zdrojovým reťazcom.
výskyt zhody: Voliteľné celé číslo označujúce, ktorá zhoda sa má vrátiť v prípade viacerých zhôd. Akceptované sú aj záporné celé čísla a umožňujú spätný prístup k zhodám, takže -1 je posledná zhoda a tak ďalej. Ak sa zadá 0, vráti sa súbor všetkých zhôd. Ak sa vynechá, vráti sa prvá zhoda.
výskyt zaznamenávaných skupín: Voliteľné celé číslo označujúce, ktorá zaznamenaná skupina v rámci zhody má byť vrátená v prípade, že v regulárnom výraze sú zaznamenané skupiny. Záporné hodnoty nie sú akceptované. Ak sa 0, vráti sa súbor všetkých zaznamenaných skupín. Ak sa vynechá, vráti sa celá zhoda.
Poznámky
Reťazec regulárneho výrazu musí spĺňať normu ICU.
Príklady |
|---|
Ak máte dáta, ktoré sa jednoducho nezmestia do riadkov a stĺpcov hárka, na ich zjednodušenie môžete použiť REGEX.EXTRACT. Napríklad v tabuľke nižšie majú dáta istú štruktúru, ale môže byť náročné dáta manuálne oddeliť do viacerých buniek na kontrolu. |
A | |
|---|---|
1 | Užívateľské hodnotenia |
2 | Email: jtalma@icloud.com Meno: Julie Talma Dátum: 17/05/2021 |
3 | Email: danny_rico@icloud.com Meno: Danny Rico Dátum: 02/06/2021 |
Na vyriešenie tohto problému môžete do tabuľky pridať ďalšie stĺpce pre hodnoty ako sú Meno, Email, Hodnotenie a Dátum, a potom pomocou funkcie REGEX.EXTRACT nájsť dáta, ktoré potrebujete, a vrátiť ich v bunke. Napríklad na vrátenie mena môžete zadať tento vzorec: 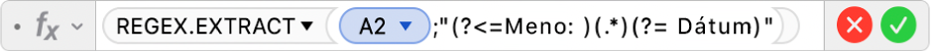 V tomto vzorci sa používajú tieto argumenty:
Tento vzorec je možné zopakovať pre každý riadok dát, aby sa vrátilo meno každej osoby, ktorá odpovedala v prieskume, tak, že zmeníte zdrojový reťazec, aby existovala zhoda s inými bunkami, ktoré obsahujú informácie o užívateľských hodnoteniach. |
Na vyriešenie tohto problému môžete do tabuľky pridať ďalšie stĺpce pre hodnoty ako sú Meno, Email, Hodnotenie a Dátum, a potom pomocou funkcie REGEX.EXTRACT nájsť dáta, ktoré potrebujete, a vrátiť ich v bunke. Napríklad môžete zadať tento vzorec: ![Editor vzorcov zobrazujúci vzorec =REGEX.EXTRACT(A2,"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}")](https://help.apple.com/assets/69AF220FB83737E52408B980/69AF25E3CCD56EDE83064898/sk_SK/2d8c8be87ed86450df51fb44257d31cf.png) V tomto vzorci sa používajú tieto argumenty:
|
Reorganizácia dát zo zoznamu pomocou argumentu výskyt zhody |
|---|
Niekedy môžete mať k dispozícii dáta ako v tabuľke nižšie (nazvanej Dodávatelia), ktorá zoskupuje hodnoty v bunke: |
Dodávateľ | Položka |
|---|---|
A | Šošovica, Fazuľa Garbanzo, Fazuľa Lima |
B | Jablká, Pomaranče, Citróny |
C | Quinoa, Ryža, Chia |
Ak chcete oddeliť hodnoty podľa obchodu a postavenia, najprv môžete vytvoriť novú tabuľku ako napríklad tabuľka nižšie: |
A | B | C | D | |
|---|---|---|---|---|
1 | Postavenie | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
Ak chcete, aby sa vrátila hodnota Šošovica, položka s najvyšším postavením pre Dodávateľa A, môžete použiť tento vzorec v bunke B2 novej tabuľky. Vráti sa Šošovica, položka s najvyšším postavením pre Dodávateľa A:  V tomto vzorci sa používajú tieto argumenty:
|
Vzorec vyššie je možné ľahko upravovať a dokončiť tak tabuľku pre ďalších dodávateľov a položky.
|
Ďalšie príklady |
|---|
A1 môže byť „marina@example.com john@example.ca mike@example.de“. =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") vráti „marina@example.com“. =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2) vráti „john@example.ca“. =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; -1) vráti „mikeexample.de“. =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 1; 1) vráti „marina“. =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2; 2) vráti „example.ca“. |