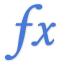
PROJ.LIN
A função PROJ.LIN retorna uma matriz de estatísticas para uma linha reta que melhor se ajusta aos dados fornecidos usando o método dos mínimos quadrados.
PROJ.LIN(valores y conhecidos; valores x conhecidos; intersecção eixo y não zero; mais estatíst)
valores y conhecidos: Uma coleção que contém os valores y conhecidos. valores y conhecidos deve conter valores numéricos ou valores de data/hora. Se houver apenas uma coleção de valores x conhecidos, os valores y conhecidos podem ser de qualquer tamanho. Se houver mais de uma coleção de valores x conhecidos, os valores y conhecidos podem ser uma coluna ou uma linha que contém os valores, mas não ambos.
valores x conhecidos: Uma coleção opcional que contém os valores x conhecidos. valores x conhecidos deve conter valores numéricos ou valores de data/hora. Se omitido, será entendido que é um conjunto do mesmo tamanho dos valores y conhecidos começando por 1 — por exemplo, 1, 2, 3 se existirem três valores y conhecidos. Se houver apenas um conjunto de valores x conhecidos, valores x conhecidos, se especificado, deve ser do mesmo tamanho que valores y conhecidos. Se houver mais de um conjunto de valores x conhecidos, cada linha/coluna de valores x conhecidos é considerada como um conjunto e o tamanho de cada linha/coluna deve ser do mesmo tamanho que a linha/coluna de valores y conhecidos.
intersecção eixo y não zero: Um valor modal opcional que especifica como a intersecção y (constante b) deve ser calculada.
normal (1, VERDADEIRO ou omitido): O valor da intersecção y (constante b) deve ser calculado normalmente.
forçar valor 0 (0, FALSO): O valor da intersecção do eixo y (constante b) deve ser forçado a ser 0.
mais-estatíst: Um valor modal opcional que especifica se as informações estatísticas adicionais devem ser retornadas.
nenhuma estatíst. adicional (0, FALSO ou omitido): Não retorna estatísticas de regressão adicionais na matriz retornada.
estatíst. adicionais (1, VERDADEIRO): Retorna estatísticas de regressão adicionais na matriz retornada.
Observações
Os valores exibidos pela função estão em uma matriz. Um método de leitura dos valores na matriz é usar a função ÍNDICE. Você pode envolver a função PROJ.LIN dentro da função ÍNDICE: =ÍNDICE(PROJ.LIN(valores y conhecidos; valores x conhecidos; intersecção de eixo y; mais estatíst); y; x) onde y e x são o índice da coluna e da linha para o valor desejado.
Se as estatísticas adicionais não são retornadas (mais-estatíst é FALSO), a matriz retornada tem uma linha de profundidade. A quantidade de colunas é igual ao número de conjuntos de valores x conhecidos mais 1. Essa quantidade contém as inclinações das linhas (um valor para cada linha/coluna dos valores x) em ordem inversa (o primeiro valor se relaciona com a última linha/coluna dos valores x) e, depois, o valor para b, o ponto de intersecção.
Se as estatísticas adicionais forem retornadas (mais-estatíst é VERDADEIRO), a matriz conterá cinco linhas. Consulte imediatamente as informações adicionais sobre essa matriz seguindo os exemplos.
Exemplos |
|---|
Dada a seguinte tabela de valores x conhecidos (células A2:A6) e valores y conhecidos (células B2:B6): |
A | B | |
|---|---|---|
1 | X | Y |
2 | 0 | -1 |
3 | 8 | 10 |
4 | 9 | 12 |
5 | 4 | 5 |
6 | 1 | 3 |
=ÍNDICE(PROJ.LIN(A2:A6; B2:B6; 1; 0); 1) retorna aproximadamente 0,752707581227437, dado um valor normal (1) para intersecção eixo y não zero. Esta é a inclinação de linha de melhor ajuste, porque especificamos que queríamos o primeiro valor da matriz retornada por ÍNDICE e só especificamos um conjunto de valores x conhecidos. =ÍNDICE(PROJ.LIN(A2:A6; B2:B6; 1; 0); 2) retorna aproximadamente 0,0342960288808646, que é b, o ponto de intersecção da linha de melhor ajuste. O ponto intersecção foi retornado porque especificamos que queríamos o segundo valor da matriz retornada por ÍNDICE, que seria o segundo valor porque só especificado um conjunto de valores x conhecidos. |
Conteúdo da matriz de estatísticas adicionais
PROJ.LIN pode incluir informações estatísticas adicionais na matriz retornada pela função. Para os propósitos da discussão a seguir, suponha que há cinco conjuntos de valores x conhecidos, além dos valores y conhecidos. Suponha, ainda, que os valores x conhecidos estão em cinco linhas ou colunas da tabela. Com base nisso, a matriz retornada por PROJ.LIN conteria os valores a seguir.
1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
1 | S5 | S4 | S3 | S2 | S1 | b |
2 | SE5 | SE4 | SE3 | SE2 | SE1 | SEb |
3 | C | SEy | ||||
4 | F | DF | ||||
5 | R1 | R2 |
A linha 1, coluna 1 contém o S5 (a inclinação do quinto grupo de valores x conhecidos) continuando até a coluna 5, a qual conteria o S1 (a inclinação para o primeiro conjunto de valores x conhecidos). Observe que a inclinação referente a cada grupo de valores x conhecidos é retornada na ordem inversa.
A última célula na linha 1 contém b, o ponto de intersecção y para os valores x conhecidos. No nosso exemplo, isso seria a linha 1 e coluna 6.
A linha 2, coluna 2 contém o SE5 (o erro-padrão para o coeficiente associado com o quinto conjunto de valores x conhecidos) continuando até a coluna 5, a qual conteria o SE1 (o coeficiente de erro-padrão para o primeiro conjunto de valores de x conhecidos). Estes valores são retornados em ordem inversa, isto é, se há cinco conjuntos de valores x conhecidos, o valor para o quinto conjunto é o primeiro a ser exibido na matriz. Esta é a mesma forma que os valores de inclinação são retornados.
A última célula da linha 2 contém o SE b, o erro-padrão associado ao valor de interseção y (b). No nosso exemplo, isso seria a linha 2 e coluna 6.
Linha 3, coluna 1 contém C, o coeficiente de determinação. Esta estatística compara os valores y reais e estimados. Se for 1, não há diferença entre o valor y estimado e o valor y real. Isto é conhecido como correlação perfeita. Se o coeficiente de determinação é 0, não há correlação e a equação de regressão fornecida não é útil para prever um valor y.
Linha 3, coluna 2 contém o SEy, o erro padrão associado à estimativa do valor y.
Linha 4, coluna 1 contém F, o valor F observado. O valor F observado pode ser usado para ajudar a determinar se a relação observada entre as variáveis dependentes e independentes ocorre por acaso.
Linha 4, coluna 2 contém DF, os graus de liberdade. Usa as estatísticas de graus de liberdade para ajudar a determinar um nível de confiança.
Linha 5, coluna 1 contém R1, a soma de regressão de quadrados.
Linha 5, coluna 2 contém R2, a soma residual de quadrados.
Eis algumas coisas a considerar sobre a matriz de estatísticas adicionais:
Não importa se os valores x conhecidos e os valores y conhecidos estão em linhas ou colunas. Em qualquer dos casos, a matriz exibida é ordenada por linhas, conforme ilustrado na tabela.
O exemplo supõe cinco conjuntos de valores x conhecidos. Se houvesse mais ou menos que cinco, o número de colunas da matriz exibida seria alterado de acordo (esse número é sempre igual à quantidade de conjuntos de valores x conhecidos mais 1), mas o número de linhas permaneceria constante.
Se as estatísticas adicionais não forem especificadas nos argumentos de PROJLIN, a matriz exibida é igual à primeira linha apenas.