REGEX.EXTRACT
The REGEX.EXTRACT function returns the matches or capture groups in a match of a given regular expression in a source string.
REGEX.EXTRACT(source-string, regular-expression-string, match-occurrence, capture-group-occurrence)
source-string: A string value to be matched against.
regular-expression-string: A string value representing a regular expression, used to match against source-string.
match-occurrence: An optional integer indicating which match should be returned, in case there are multiple matches. Negative integers are accepted and allow accessing the matches backwards, so -1 is the last match, and so on. If 0 is given, an array of all matches will be returned. If omitted, the first match is returned.
capture-group-occurrence: An optional integer indicating which capture group within a match should be returned, in case there are capture groups in the regular expression. Negative values are not accepted. If 0 is returned, an array of all capture groups will be returned. If omitted, the entire match is returned.
Notes
The regular-expression-string has to conform to the ICU standard.
Examples |
|---|
If you have data that doesn’t easily fit into the rows and columns of a spreadsheet, you can use REGEX.EXTRACT to simplify. For example, in the table below, the data has some structure but it can be difficult to manually separate the data into multiple cells per review. |
A | |
|---|---|
1 | User Reviews |
2 | Email: jtalma@icloud.com Name: Julie Talma Date: 05/17/2021 |
3 | Email: danny_rico@icloud.com Name: Danny Rico Date: 06/02/2021 |
To fix this, you can add more columns to the table for Name, Email, Rating and Date and then use REGEX.EXTRACT to find the data you want and return it in the cell. For example, you could enter the following formula to return a name: 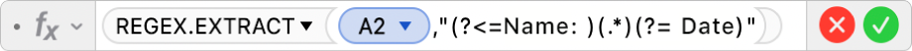 In this formula, the following arguments are used:
This formula can be repeated for each row of data to return the name of each person who responded to the survey by changing source-string to match the other cells containing user review information. |
To fix this, you can add more columns to the table for Name, Email, Rating and Date and then use REGEX.EXTRACT to find the data you want and return it in the cell. For example, you could enter the following formula: ![The Formula Editor showing the formula =REGEX.EXTRACT(A2,"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}")](https://help.apple.com/assets/620C31B9B68FCB4E9710C49E/620C31BDB68FCB4E9710C4BD/en_AU/163c35aaef2fd6a143c84ba471bce0a9.png) In this formula, the following arguments are used:
|
Reorganise data from a list with match-occurrence |
|---|
Sometimes, you may have data like the table (titled Suppliers) below, which groups values together in a cell: |
Supplier | Item |
|---|---|
A | Lentils, Garbanzo, Lima |
B | Apples, Oranges, Lemons |
C | Quinoa, Rice, Chia |
To separate the values based on store and rank, you can first create a new table, like the table below: |
A | B | C | D | |
|---|---|---|---|---|
1 | Rank | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
To return Lentils, the top ranked item for Supplier A, you can use a formula like this in cell B2 of the new table to return Lentils, the top ranked item for Supplier A:  In this formula, the following arguments are used:
|
The formula above can easily be modified to complete the table for the other suppliers and other items.
|
Additional examples |
|---|
Let A1 be "marina@example.com john@example.ca mike@example.de". =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") returns "marina@example.com". =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 2) returns "john@example.ca". =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", -1) returns "mike@example.de". =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 1, 1) returns "marina". =REGEX.EXTRACT(A1, "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 2, 2) returns "example.ca". |