REGEX.EXTRACT
Funkce REGEX.EXTRACT vrací shody nebo zachycené skupiny ve shodě se zadaným regulárním výrazem ve zdrojovém řetězci.
REGEX.EXTRACT(zdrojový-řetězec; řetězec-regulárního-výrazu; výskyt-shod; výskyt-zachytávaných-skupin)
zdrojový-řetězec: Řetězcová hodnota pro porovnání a zjištění, zda nastane shoda.
řetězec-regulárního-výrazu: Řetězcová hodnota reprezentující regulární výraz, který se porovnává se zdrojovým-řetězcem.
výskyt-shod: Nepovinná celočíselná hodnota udávající shodu, která má být vrácena, když těchto shod existuje více. Lze použít i záporná čísla. Ta udávají shody v obráceném pořadí, takže například -1 je poslední shoda atd. Při zadání čísla 0 bude vráceno pole se všemi shodami. Je-li parametr vynechán, funkce vrátí první shodu.
výskyt-zachytávaných-skupin: Nepovinná celočíselná hodnota určující, kolikátá zachycená skupina má být vrácena, jestliže regulární výraz obsahuje zachytávané skupiny. Záporné hodnoty nelze použít. Při zadání čísla 0 bude vráceno pole se všemi zachycenými skupinami. Je-li parametr vynechán, funkce vrátí celou shodu.
Poznámky
Řetězec-regulárního-výrazu musí splňovat podmínky standardu ICU.
Příklady |
|---|
Pokud máte data, která se snadno nevejdou do řádků a sloupců tabulky, můžete pro zjednodušení použít funkci REGEX.EXTRACT. Například v níže uvedené tabulce mají data určitou strukturu, ale může být obtížné je ručně rozdělit do více buněk pro každé zobrazení. |
A | |
|---|---|
1 | Hodnocení uživatelů |
2 | E-mail: jtalma@icloud.com Jméno: Julie Talma Datum: 17.05.2021 |
3 | E-mail: danny_rico@icloud.com Jméno: Danny Rico Datum: 02.06.2021 |
Toto lze vyřešit tak, že do tabulky přidáte další sloupce pro Jméno, E-mail, Hodnocení a Datum a pak pomocí funkce REGEX.EXTRACT vyhledáte požadovaná data a vrátíte je v buňce. Pro vrácení jména můžete zadat například následující vzorec: 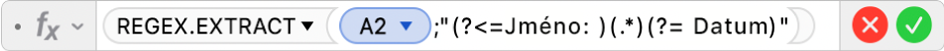 V tomto vzorci byly použity následující argumenty:
Tento vzorec lze opakovat pro každý řádek dat a vrátit jména všech osob, které odpověděly na průzkum, změnou zdrojového-řetězce tak, aby odpovídal ostatním buňkám obsahujícím informace o hodnocení uživatele. |
Toto lze vyřešit tak, že do tabulky přidáte další sloupce pro Jméno, E-mail, Hodnocení a Datum a pak pomocí funkce REGEX.EXTRACT vyhledáte požadovaná data a vrátíte je v buňce. Můžete zadat například následující vzorec: ![Editor vzorců zobrazující vzorec =REGEX.EXTRACT(A2;"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}")](https://help.apple.com/assets/626C4EEE69937F618B403B14/626C4EF369937F618B403B34/cs_CZ/1a5aba2723ab162d89606c178a505c36.png) V tomto vzorci byly použity následující argumenty:
|
Změna uspořádání dat pomocí výskytu-shod |
|---|
Někdy můžete mít data jako v tabulce (s názvem Dodavatelé) níže, která seskupuje hodnoty v buňce: |
Dodavatel | Položka |
|---|---|
A | Čočka, Cizrna, Fazole |
B | Jablka, Pomeranče, Citróny |
C | Quinoa, Rýže, Chia semínka |
Chcete-li oddělit hodnoty podle obchodu a umístění hodnoty, můžete nejprve vytvořit novou tabulku (jako je tabulka níže): |
A | B | C | D | |
|---|---|---|---|---|
1 | Umístění hodnoty | A | B | C |
2 | 1 | |||
3 | 2 | |||
4 | 3 |
Má-li se vrátit čočka, nejlépe hodnocená položka pro dodavatele A, můžete v buňce B2 v nové tabulce použít vzorec, který vrátí čočku, nejlépe hodnocenou položku pro dodavatele A:  V tomto vzorci byly použity následující argumenty:
|
Výše uvedený vzorec lze snadno upravit a doplnit tabulku pro ostatní dodavatele a další položky.
|
Další příklady |
|---|
Předpokládejme, že buňka A1 obsahuje řetězec „marina@example.com john@example.ca mike@example.de“. Vzorec =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})") vrátí řetězec „marina@example.com“. Vzorec =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})", 2) vrátí řetězec „john@example.ca“. Vzorec =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; -1) vrátí řetězec „mikeexample.de“. Vzorec =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 1; 1) vrátí „marina“. Vzorec =REGEX.EXTRACT(A1; "([A-Z0-9a-z._%+-]+)@([A-Za-z0-9.-]+\.[A-Za-z]{2,4})"; 2; 2) vrátí řetězec „example.ca“. |