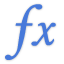
COUNTIF
تُرجع عدد الخلايا الموجودة في إحدى المجموعات التي تتوافق مع الشرط المذكور.
COUNTIF(مصفوفة-اختبار; الشرط)
مصفوفة-اختبار: المجموعة التي تحتوي على القيم ليتم اختبارها. ويُمكن أن تحتوي مصفوفة-اختبار على أية قيمة.
الشرط: هو عبارة عن تعبير يقوم بمقارنة أو اختبار القيم والنتائج في القيمة البوليانية صواب أو خطأ. يمكن أن يتضمن الشرط معاملات مقارنة، ثوابت، معامل التسلسل بعلامة العطف، مراجع، وأحرف بدل. يمكنك استخدام أحرف البدل لمطابقة أي حرف أحادي أو عدة أحرف في التعبير. يمكنك استخدام ? (علامة استفهام) لتمثيل حرف واحد، * (علامة نجمة) لتمثيل عدة أحرف، و~ (التلدة) لتحديد أنه يجب مطابقة الحرف التالي بدلاً من استخدامه كحرف بدل.
ملاحظات
تتم مقارنة كل مصفوفة اختبار مع الشرط. إذا كانت القيمة تتوافق مع اختبار الشرط، فيتضمنها الحساب.
أمثلة |
|---|
إن المعلومات المذكورة في الجدول التالي ليست لها معنى، إنما تكمُن أهميتها في تفسير نوع متغيرات الدوال التي تشتمل عليها الدالة COUNTIF في نتائجها. الجدول التالي المعطى: |
A | B | C | D | |
|---|---|---|---|---|
1 | 100 | 200 | 300 | 400 |
2 | lorem | ipsum | ipsum | sit |
3 | 100 | 200 | 300 | sit |
4 | صواب | صواب | خطأ | خطأ |
5 | 200 | 400 |
=COUNTIF(A1:D1؛ ">٠") تُرجع ٤، لأن جميع الخلايا في المجموعة لديهم قيمة أكبر من الصفر. =COUNTIF(A3:D3؛ ">=١٠٠") تُرجع ٣، لأن هناك ثلاثة أرقام أكبر من ١٠٠ أو تعادلها، ويتم تجاهل القيمة النصية في المقارنة. =COUNTIF(A1:D5؛ "=ipsum") تُرجع ١، لأن السلسلة النصية "ipsum" تظهر مرة واحدة في المجموعة المُشار إليها بالنطاق. =COUNTIF(A1:D5؛ "=*t") تُرجع ٢، لأن السلسلة التي تنتهي بالحرف "t" تظهر مرتين في المجموعة المُشار إليها بالنطاق. |
المثال ــــ نتائج الاستبيان |
|---|
إن هذا المثال يُوضح كل التفسيرات معاً المستخدمة خلال الدوال الإحصائية. وهي تعتمد على الاستبيان الافتراضي. هذا الإحصاء قصير (خمسة أسئلة فقط) وسيُقدم لعدد محدود للغاية من المتلقين.(١٠) على أن يتم إجابة كل سؤال حسب المقياس من ١ إلى ٥ (ربما النطاق من "أبداً" إلى "دائماً")، أو لم يتم الإجابة عليه. وسيتم تعيين رقم (رقم تعريف) ما لكل استبيان قبل الإرسال بالبريد الإلكتروني. ويُبين الجدول التالي النتائج. تتم الإشارة إلى الأسئلة التي تمت الإجابة عليها خارج النطاق (غير صحيحة) أو لم يتم الإجابة عليها، بخلية فارغة في الجدول. |
A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
1 | رقم التعريف | س١ | س٢ | س٣ | س٤ | س٥ |
2 | 101 | 5 | 4 | 4 | 3 | 4 |
3 | 105 | 3 | 2 | 2 | 3 | 3 |
4 | 102 | 4 | 4 | 4 | 4 | |
5 | 104 | 3 | 4 | 2 | 4 | 3 |
6 | 107 | 4 | 3 | 3 | ||
7 | 106 | 4 | 3 | 3 | 4 | |
8 | 109 | 3 | 4 | 1 | 3 | 4 |
9 | 111 | 5 | 2 | 2 | 5 | 3 |
10 | 121 | 4 | 2 | 3 | 3 | 4 |
11 | 115 | 3 | 3 | 3 | 3 |
لتفسير بعض الدوال، على افتراض أن رقم الاستبيان يتضمن بادئة هجائية، وأن المقياس هو A إلى E بدلاً من ١ إلى ٥. وبهذا سيبدو الجدول كالتالي: |
A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
1 | رقم التعريف | س١ | س٢ | س٣ | س٤ | س٥ |
2 | 101 | E | D | D | C | D |
3 | 105 | C | B | B | C | C |
4 | 102 | D | D | D | D | |
5 | 104 | C | D | B | D | C |
6 | 107 | D | C | C | ||
7 | 106 | D | C | C | D | |
8 | 109 | C | D | A | C | D |
9 | 111 | E | B | B | E | C |
10 | 121 | D | B | C | D | |
11 | 115 | C | C | C | C | C |
يُمكنك الجمع بين المعلومات التي تدور حول نتائج الاستبيان، باستخدام جدول البيانات وبعض الدوال الإحصائية المتاحة. وضع في اعتبارك أن المثال سيكون صغير لهدف ما، وقد يترتب عن ذلك وضوح النتائج. بالرغم أنه إذا كان لديك نحو ٥٠ متلقي أو ١٠٠ أو أكثر، ومع احتمال وجود أسئلة كثيرة، قد لا تصبح النتائج واضحة. |
الدوال ومتغيراتها | وصف النتيجة |
|---|---|
=CORREL(B2:B11؛ C2:C1) | تحدد الارتباط بين السؤالين ١ و٢ بواسطة تحليل الانحدار الخطي. فالارتباط يشير إلى قياس إلى أي مدى يتغير متغيران معاً (في هذه الحالة، نشير إلى الإجابات على أسئلة الاستبيان). وعلى وجه الخصوص، يبدو هذا في السؤال: إذا أجاب المتلقي على السؤال رقم ١ بقيمة أكبر من متوسط السؤال رقم ١ (أو أقل)، هل سيجيب على السؤال رقم ٢ أيضاً بقيمة أكبر من متوسط السؤال رقم ٢ (أو أقل)؟ في هذه الحالة، ليس شرطاً أن يكون المتلقون مترابطين بشكل جيد. (-٠٫١٧٣٢) |
=العدد(A2:A11) أو =COUNTA(A2:A11) | تحدد الرقم الإجمالي للاستبيانات المرتجعة. (١٠) ولاحظ أنه إذا كان رقم الاستبيان غير رقمي، فستحتاج إلى استخدام COUNTA بدلا من العدد. |
=العدد(B2:B11) أو =COUNTA(B2:B11) | تحدد إجمالي عدد الإجابات على السؤال الأول (٩). بتعميم هذه الصيغة على الصف، يُمكنك تحديد العدد الإجمالي للإجابات على كل سؤال. ونظراً لأن جميع البيانات رقمية، فيُمكن لـ COUNTA أن تُرجع نفس النتائج. بالرغم من أنه إذا استخدم الاستبيان من A إلى E بدلا من ١ إلى ٥، فستحتاج إلى استخدام COUNTA لحساب إجمالي النتائج. |
=COUNTBLANK(B2:B11) | تحدد عدد الخلايا الفارغة، التي تمثل الإجابات غير الصالحة أو عدم وجود إجابات. وإذا قمت بتعميم الصيغة على الصف، ستجد أن السؤال ٣ (العمود D) لديه ٣ ردود غير صالحة أو لم يتم الإجابة عليها. وقد يتسبب هذا في أن تنظر إلى السؤال الوارد بالاستبيان لترى ما إذا كان مثير للخلاف أو أن تركيبته اللفظية ركيكة، طالما ليست هناك أي أسئلة أخرى غير صحيحة أو لم يتم الإجابة عليها. |
=COUNTIF(B2:B11؛ "=٥") | تحدد عدد المتلقين الذين يعطون ٥ لسؤال محدد (في هذه الحالة، السؤال ١). إذا قمت بتعميم هذه الصغة على الصف، ستعلم أن السؤالين ١ و٤ لديهم متلقين قد أعطوا السؤال ٥. وفي حالة استخدام الاستبيان من A إلى E الخاصة بالنطاق، فستستخدم =COUNTIF(B2:B11؛ "=E"). |
=COVAR(B2:B11؛ C2:C11) | تحدد التباين بين السؤالين ١ و٢. فالتباين يشير إلى قياس إلى أي مدى يتغير متغيران معاً (في هذه الحالة، نشير إلى الإجابات على أسئلة الاستبيان). وعلى وجه الخصوص، يبدو هذا في السؤال: إذا أجاب المتلقي على السؤال رقم ١ بقيمة أكبر من متوسط السؤال رقم ١ (أو أقل)، هل سيجيب على السؤال رقم ٢ أيضاً بقيمة أكبر من متوسط السؤال رقم ٢ (أو أقل)؟ ملاحظة: لن يعمل COVAR مع الجدول باستخدام المقياس من A إلى E، لأنها تتطلب متغيرات دوال رقمية. |
=STDEV(B2:B11) أو STDEVP(B2:B11) | تحدد الانحراف المعياري—مقياس واحد للتشتت—للإجابات للسؤال ١. إذا قمت بتعميم هذه الصيغة في الصف، سترى أن الإجابات على السؤال ٣ قد اتخذت أعلى انحراف معياري. إذا كانت النتائج تُمثل الردود من المحتوى التي يتم دراستها بأكملها، بخلاف العينة، سيتم استخدام STDEVP بدلاً من STDEV. لاحظ أن STDEV هي الجذر التربيعي لـ "تباين". |
=تباين(B2:B11) أو =VARP(B2:B11) | تحدد التباين—مقياس واحد للتشتت—للإجابات للسؤال ١. إذا قمت بتعميم هذه الصيغة في الصف، سترى أن الإجابات على السؤال ٥ قد اتخذت أقل انحراف معياري. إذا كانت النتائج تُمثل الردود من المحتوى التي يتم دراستها بأكملها، بخلاف العينة، سيتم استخدام VARP بدلاً من تباين. لاحظ أن تباين هي مربع STDEV. |